Data News — Week 22.29
Data News #22.29 — How F1 is using data? Summer data games, dbt-helper extension, stop using CTEs, Airflow 👑, summer community days.

Hello 🏎, this weekend the French Formula 1 Grand Prix is taking place. As I'm going there this is a slightly shorter edition. But I also tried to do a curation regarding how F1 teams are using data maximize performance.
Data fundraising 💰
- Equals raised $6.6m seed round to replace Excel. Every ~15-20 years we achieve a truly new innovation 🙃. In 1985 Excel was created, later in 2006 Google Sheets was released and changed the way we use sheets. Equals could be the next evolution. Natively the SaaS app connects to your warehouse and displays your data in a tabular format after a query (graphical built or SQL). The UI looks neat. Maybe this is what we were all waiting to fix data last kilometre.
- OpenAI released in beta DALL·E 2 image generation API. After the free tier it'll cost 15$ per 460 generated images. To be honest I feel this is quite expensive. But maybe this is the cost to avoid having the web spammed with fake images.
How F1 teams are using data?
To be honest it has been very hard to find public informations regarding this topic. All the teams are secret about the matter — I think we can understand why. This is sad because as F1 is a performance sport where every second count. We could learn a lot when it comes to real-time data use-cases.
So while looking information I mainly navigated through marketing stuff but I found some really interesting YouTube videos about how Formula teams are using data:
- F1 Explained: How does telemetry data help teams go faster?
- AWS related posts: How FORMULA 1 insights are powered by AWS, compute the fastest driver is in Formula 1 and F1 insights about car analysis and development
- How TIBCO uses data science: from simulators to real-life — An hour presentation about how simulation data is got in streaming to be visualized to help e-sport teams.
- Fast cars and big data, how streaming can help Formula 1? This presentation shows that Formula 1 is not really different than the usual old data stack (in 2017).
- Understand formula racing time series analysis with this short 2mn video.
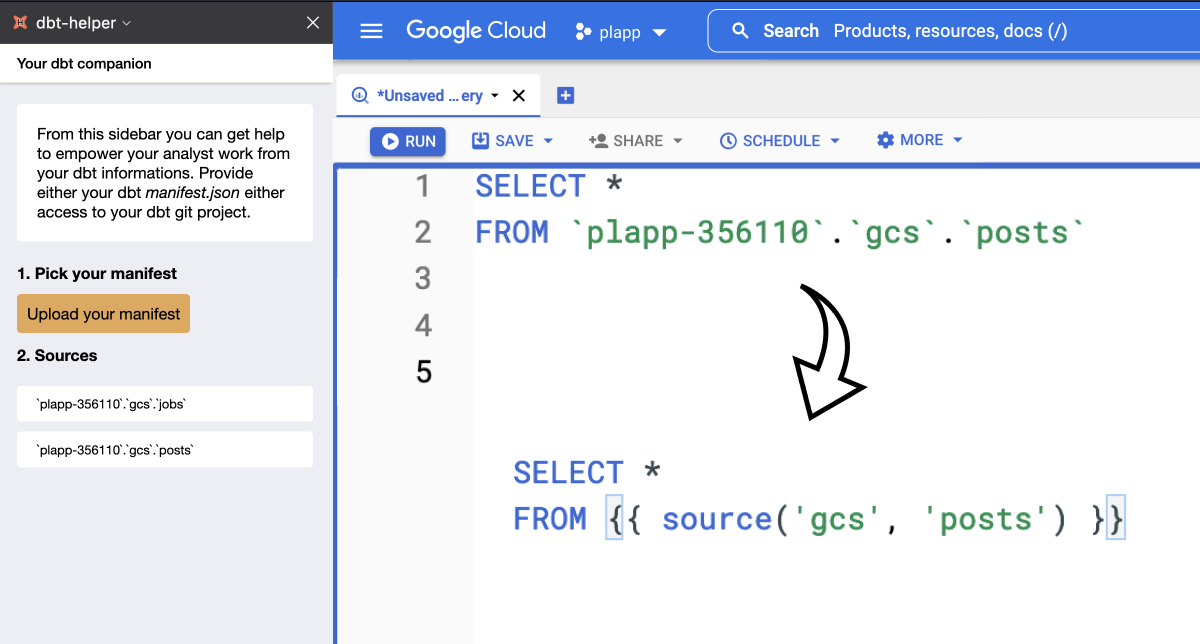
Your next favourite dbt browser extension
Yesterday I have worked on a experiment I had in mind since last year. This is a browser extension that helps you working with BigQuery and Snowflake when using dbt. The extension overrides the default clipboard behaviour to replace table names by the corresponding ref or source.
You can find a demo of the extension on my LinkedIn post.
Stop using so many CTEs
Claire, one of the greatest thinker about analytics engineering job, took position regarding CTEs. You know CTEs. The syntax everyone decided to use in order to avoid subqueries to create more linear queries.
For Claire, we should stop using so many CTEs. I do agree, in today's data world we reached a point where CTEs are so deeply integrated in our data stacks that it could bring more downsides than perks. The proposed solution is the Chained SQL — a feature in Hex — but philosophically it can apply everywhere. Smaller SQL pieces to bring modularity.
Airflow is still the king
Once in a while I cense Airflow because it's like my first data love. This week Jarek — who is an active Airflow committer and PMC — also shared this love. He describes how generic transfers are designed in Airflow and how simple it is to use them. Personally I've been always convinced that writing a transfer DAG in Airflow is so simple that dedicated EL tooling needs is not so strong. Jarek shows the way.
If you are still starting with Airflow David started a series with an introduction post. On the other side Seattle Data Guy put words on this infinite debate: why data engineers love/hate Airflow. When jumping to the real word, Jellysmack explains how they used Airflow to orchestrate in production data science jobs.
And finally you still think you need to redevelop yourself an orchestrator you can get inspiration on how Criteo developed BigDataflow, their internal DAGs-based scheduler/orchestrator.
Holidays ☀️
Like in every good newspaper during the holidays there are some games and especially crosswords. So I tried to give you a small crossword to enjoy data while at the beach — or at the office while others are enjoying the sand. Try the grid online.

If you feel the crossword is too easy and you have more time to play I recommend you to use SQLordle — a wordle but only with SQL keywords.
PS: if you want more crosswords just tell me I'll try to make others until the end of the summer.
Fast News ⚡️
- Event — Summer community days. Next week will take place an online community conference organized by Census around analytics engineering. In 3 tracks it'll mix keynotes, advices and technical presentations. The agenda is packed and personally I'd like to watch few of the confs.
- Airflow is finally working with ARM — But starting from version 2.3.
- Learn more about Apache Arrow — Arrow is one of the hidden hero of all the data stacks. Used by Parquet, Spark, Snowflake among others Arrow became the leading library when data communication is needed. This is a small Twitter thread detailing David learnings.
- Understand indexes — Joaquin explained what everyone should know about databases indexes. This is a great starting point.
- Is data scientist still the sexiest job of the 21st century? — HBR post 10 years after their initial post. 1700 words and data engineer mentioned only once.
- My Journey in data — Neelesh shared his journey in the data world. From Cloudera to dbt Labs the post shows what he had to learn over the years to become, today, a Staff Software Engineer (which is a good transition for the next link).
- 🇫🇷 [FR] Comprendre la vie d'une Staff Engineer — Célia from Doctolib engineering team share what is her life as Staff Engineer. This is a great example to understand the daily routine of this position. In addition Nicolas — the blog owner — wrote a post detailing how to become staff/principal engineer.


blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.