Data News — Week 22.38
Data News #22.38 — Hidden gems in dbt artifacts, understand the Snowflake query optimizer, Python untar vulnerability, fast news and ML Friday.

Bonjour vous ! Like sometimes I'm late. Today, I write the first words of the newsletter at 5PM. Which is 8h later than usual. Pardon me. In term of content it has been a huge week for me, I've prepared a meetup presentation that I enjoyed giving this Wed. It feels good to present stuff in public.
So yeah, let's talk a bit of this presentation.
Find the hidden gem in dbt artifacts
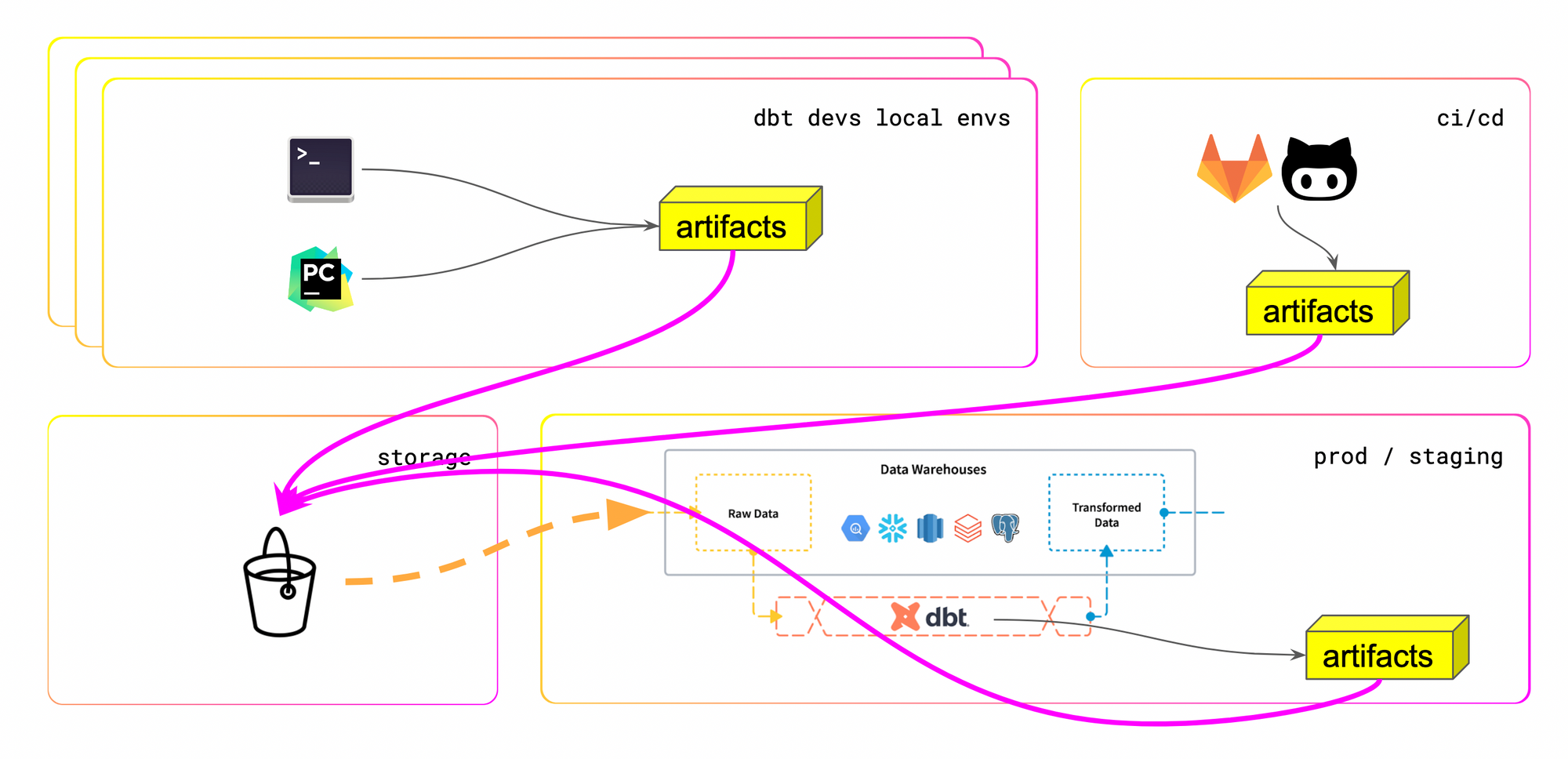
On Wednesday I made a 30 minutes presentation looking for hidden gems in dbt artifacts. The talk was a bit experimental, the idea is to show that this is possible for everyone to add context to you data infrastructure by leveraging generated artifacts. It means you can use the 4 JSON files generated to create tooling around your dbt project.
Shoemakers children are the worst shod.
Why not using the data generated by dbt artifacts to create useful data models to self-improve our data platforms?
While leveraging the 4 JSON files (manifest, run_results, sources, catalog) we could:
- Sources monitoring like in dbt Cloud
- Extends your dbt docs HTML
- Send data in your BI tool. We already have Metabase or Preset integrations.
- Enforce and visualise your data governance policy. Refuse every merge request if a model owner is not defined for instance.
- dbt observability, monitoring and alerting, have fun with analytics on your analytics.
- Create a dbt model time travel viewer. Create an automated changelog process than display your data model evolutions.
- dbt-helper — Your SQL companion
- dbt-doctor — It’s time to detect issues. Idea: a CLI tool to detect any dbt FROM leftovers to fail in CI if yes.
I also shared that every data engineer should consider the artifacts like a way to understand their customers. If you manage to get the artifacts from every envs (local, ci, staging, prod) you have the data to understand how everyone is using the tool. Especially useful if you have junior analysts lost within the tool, it'll detect silent local issues.
🔗 Here the slides of my presentation.
Closing on dbt
To finish this edito about dbt here 3 other articles I found interesting. While we live our best life by creating dbt projects the complexity of the projects will only rise in the future. By facilitating the way we creating data models we encourage the data model creation. So what does it means we you have more the 700 models written by more than 43 humans? Anna from dbt Labs wrote an introspection post about it.
Adrian also raised the complexity topic on Medium. He states that with the modern data stack and the all-SQL paradigm we wrote complex code that risks to be unmanageable.
Finally if you want to have a course on data modeling Miles from GitLab will run a CoRise on Data Modeling for the Modern Warehouse. Seems a good resources to get started at Kimball methodology.
Understanding the Snowflake query optimizer
❤️ If you had to read only one article this week it would be this one. I think Teej is doing an awesome job demystifying Snowflake internals. And he striked once again. It's time to understand how the Snowflake query optimizer works. Even if you don't use Snowflake I recommend this article to you.
The job of a query optimizer is to reduce the cost of queries without changing what they do. Optimizers cleverly manipulate the underlying data pipelines of a query to eliminate work, pare down expensive operations, and optimally re-arrange tasks.
In a nutshell the query optimizer tries to transform the badly written 500 lines query to optimized instructions for the database. In order to run the query the database will need to load data in memory and the query optimiser will try to find what is the minimal set of data the engine needs to scan in order to answer as fast as he can.
Once the database knows exactly what to read, the optimizer will rewrite the query in a more optimized syntax but logically identical. It will replace the views or functions with their underlying physical objects, unselect the useless columns (called column pruning) and push the predicates. The predicate pushdown is the step where the optimiser tries to move all the data filtering (WHEREs) as early as possible in the query.
Then it will do a join optimization. But for this I let you read it on Teej excellent post.

ML Friday 🤖
- Netflix — Machine learning for fraud detection in streaming services.
- Snowflake & Prophet (Meta) — Run forecasts directly within the warehouse with Snowpark.
- River, Redpanda and Materialize — Max developed a small Streamlit application predicting in real time taxi trip durations.
- Linear Regression explained — Once again mlu-explain created the best resource to explain how linear regression is working. While scrolling you understand how the model works.
- OpenAI — Whisper, a new model released by OpenAI to automatically detect English speech.
Fast News ⚡️
- Airflow 2.4 out, the data-aware scheduling — This new release features a new way to approach Airflow scheduling. You define datasets and relations between them. Airflow handle the logic to run DAG related to each dataset when needed. This behaviour has been introduced by Dagster months ago.
- ⚠️ 350 000 Python projects subject to a 15 years old vulnerability — CVE-2007-4559 has been discovered in August 2007 and allows an attacker to overwrite files when the archive is untared with
..relative names (I've been told that this attack also exists in zip). - BigQuery SQL functions for data cleaning — 4 useful functions like normalize, pattern_matching, safe divide and date formatting.
- 📺 Saving the planet one query at a time — A part of the data ecosystem live in a dream. The dream of the infinite resources hidden in Google or AWS. But this is as wrong as the infinite oil principle our economy is based on. The time will come to reconsider running a fancy clustered Spark job and replacing it with a local DuckDB compute. To go further the French org The Shift Project wrote a manifesto to help university shaping the next engineers.
- On DuckDB topic there is a — not self-explanatory — demo on how to combine Malloy and DuckDB to do analytics in the web browser.
- The evolution of data companies — Ben analyze the extract-load connectors vision of Portable, Airbyte and Estuary. There are 3 companies with founders coming from Liveramp, and Ben tries to see which problem from Liveramp helped them imagine the data products they run today.
- Gamification of data knowledge — How to create the best data documentation by adding gamification to the process.
- Testing & monitoring the data platform at scale — With Airflow and MonteCarlo inside.
See you next week 👻

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.