
Dear readers, already 3 months done in 2023. We are slowly approaching the 2-years anniversary of the blog and the newsletter. We are almost 3000 and once again I want to thank you for the trust. To be honest time flies and I’d have preferred to do more for the blog in the start of the year but my freelancing activities and my laziness took me so much.
By the way, recently I’ve worked with Azure tooling and I changed a bit my mind. I had tried Azure years ago and the only memory I had of it was that it was not working. Like you ask for a VM and you don’t get a VM. But obviously it changed. Except the fact that they have a pretty bad vocabulary for things, it works, and the UI is surprisingly pleasant to use.
My personal preference hierarchy changed with this experience, which is subjective, is GCP > Azure > AWS. Still one complaint I might have is about documentation, sometimes docs page are not of great quality, the presentation is pretty bad and full of usage examples when we only need complete documentation of ressources.
If you did not register next week we’ll host an online meetup about Airflow alternatives and Prefect and Dagster teams will do a demo.

PS: brace yourself, April fool's is tomorrow. I've already seen a few "jokes" on LinkedIn.
Google Data Cloud & AI Summit
Two days ago Google announced new things at their Data Cloud & AI Summit. Here a small recap of what has been announced.
Pricing changes
First, a new BigQuery pricing model. Big changes—or should I say BigChanges—the flat-rate pricing will not be accessible starting on July 5 and will be replaced by a capacity pricing similar to what Snowflake is doing. It will start at $0.04 for a slot hour. It is hard to compare to the previous flat-rate pricing but the previous pricing was more around $0.028 for a slot hour (42% increase). Still Google says that it will lower your BigQuery costs because they have the smartest autoscaler on hearth 🫠 and will run only what's perfectly needed for your queries.
Let's take an example previously you could have run 100 BigQuery slots at every moment in time for $2000 a month. Tomorrow for instance you would be able to run 160 slot hour if you use BigQuery only 10h per day for the same amount ($2000). This changes means less computing power on average for the same price but with higher peaks.
Like good news never comes alone they will also increase the on-demand pricing by 25% starting July 5. It will costs $6,25 per TB compared to $5 before.
They also announced a "significant" increase in compression performance so that you should switch you storage pricing from logical (uncompressed) to physical (compressed—the actual bytes stored on disk). Compressed storage is at least twice more expensive than uncompressed but as they announce a 12:1 (previously 10:1) compression ratio your company wallet will be the winner. The icing on the cake.
This new pricing is sad to see, excluding the increase, I believe that for years, one of the strongest advantage of BigQuery was his apparent pricing transparency. Now you need to do multiplication and open and read 5 pages to understand the pricing.
5 paragraphs about the pricing, it was unexpected.
Looker Modeler
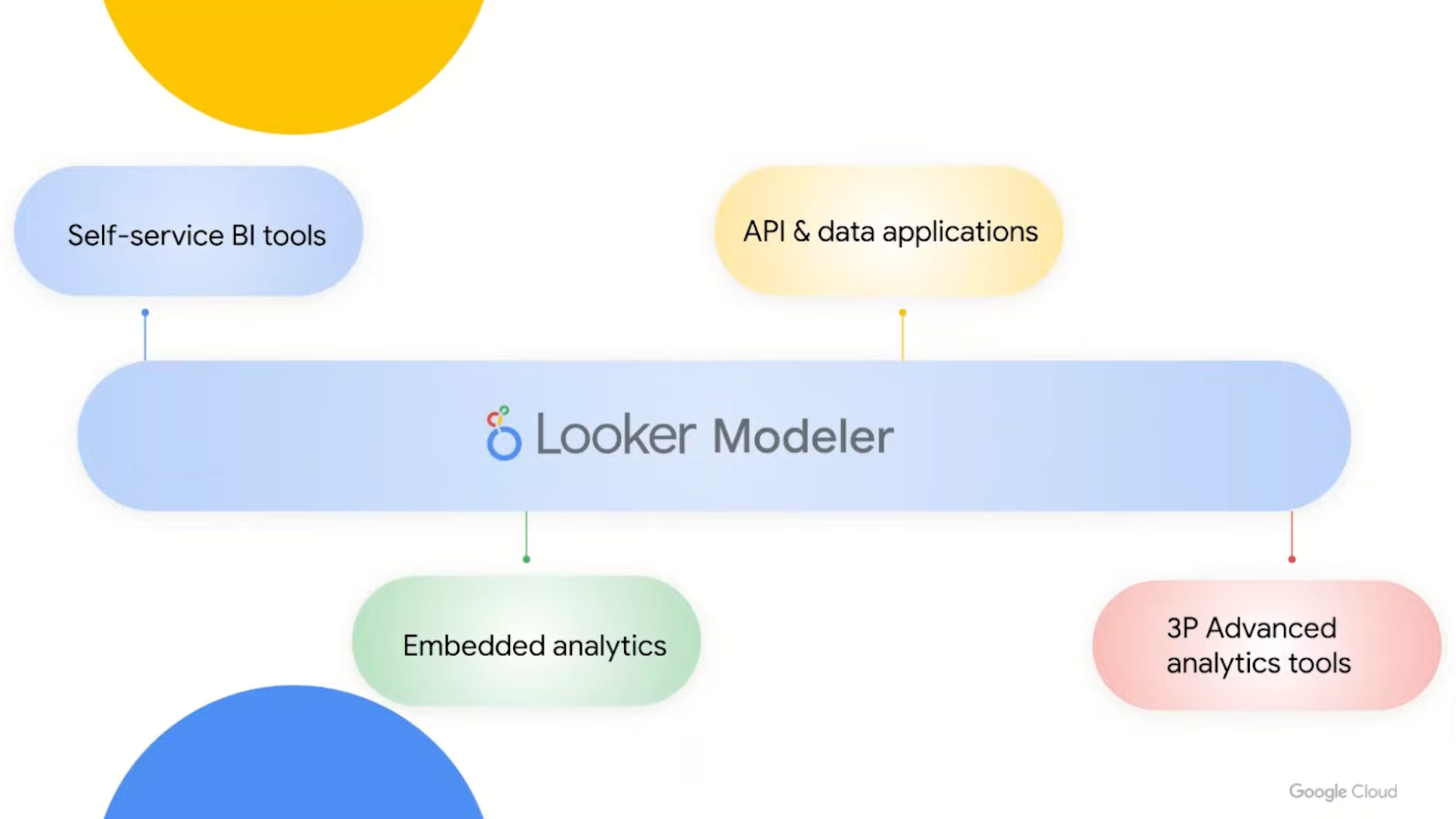
They also announced Looker Modeler, a single source of truth for BI metrics. This is finally over, we have Google take on the semantic layer and the evolution of the LookerML which was one of the first version. They created Looker Modeler as a metrics layer that will be accessible by all the application downstream.
In a nutshell it will mean—in Looker vocabulary:
- Data Engineer will create sources that will be available in Looker
- Analytics Engineer (or Data Analysts) will create Views from a table with Dimensions and Metrics thanks to the LookML
- Then AE will create Models on top of Explores—Explores are joined Views
- Then you will be able to access the Models through the Looker Modeler via a JDBC interface or a REST API.
Thanks to this we will be able to read LookML data from Tableau. Awesome!
If you teach someone SQL they can help themselves, if you teach them LookML they help everyone.
Gen App Builder
As an answer to OpenAI offering Google Cloud started to propose cloud offering around generative AI. They announced a web UI to create conversational AIs. In the demo you upload a FAQ (in CSV) and a "How to guide" (in PDF), you pick either "Chat" or "Search" mode and it will generate a app that you can give to your customers to user personalised with your data. You can also feed to the pre-trained models BigQuery tables, GCS buckets or websites URLs.
Gen AI 🤖
Google summit last section was a perfect transition to the GenAI category. Every week is richer than the previous one.
- Bill Gates published a note: The Age of AI has begun. He says that GPT being able to ace university Bio exam is the most important advance in technology since the graphical user interface in 1980. He thinks that AI will help reduce world's inequities like health inequities—I doubt that, like pills and medicine only rich and educated people will benefit AI in the end. Then he enlightens us with how AI can change health and education systems, what are the risks and the next frontiers.
- Then everyone started to freak out. An open letter has been written to ask a pause—at least 6 months—in giant AI experiments, it has been signed by almost 2000 people, with some notorious CEOs, researchers and Elon Musk. This pause should be use to develop with policymakers AI governance systems.
- Gary Marcus debated about the AI risk ≠ AGI risk. AGI means artificial general intelligence. He mainly thinks that LLMs are an “off-ramp” on the road to AGI.
- For B2B generative AI apps, is less more? — a16z, a huge US VC, predicts that we will enter in a second wave of AI called the SynthAI. Currently we generate information based on prompt, in the wave 2 we will generate insights based on information. This wave seems to be critical for B2B because AI should help decision making, but need to be concise for that.
- As a fun use-case, John wrote how we can rethink whisky search in the world of ChatGPT.
Still LLMs and semantic layers are a goods initiatives to achieve this everlasting dream. But first ask yourself, will my CEO trust a bot answering on Slack or someone from the accouting team delivering an overcrowded Excel?
Fast News ⚡️
- The data engineer is dead, long live the data plaform engineer — This is a current trend of the marker that has been accelerate by the analytics engineer appearance. As AE are, theoretically, in between DE and DA it pushes the actual roles borders further. Meaning DE will have to do more infra stuff to support analytics initiatives. This is normal and Robert adds more to the table in his blogpost. You can also check this map that explains all data roles.
- Five charts that changed the world — A 5 minutes video by the BBC that shows 5 awesome charts that changed the course of the world.
- Databend, an open-source version of Snowflake — at least this is what they claim. This week I discovered this "open-source data warehouse written in Rust". I'll try it out when I have time. If you tried it you'd love to get your feedback.
- audit_helper in dbt — A blog post that showcase how you can use dbt audit_helper package to improve your models. As the competition gets harder every week Datafold also wrote a blogpost comparing audit_helper vs. data-diff.
- dbt-checkpoint, a list of pre-commit to ensure dbt quality — A list of 40 pre-commit written in Python that you can use to improve the quality of your dbt projects. It includes the useful
check-script-has-no-table-nameto check if a there is not table name leftovers. - Strategies for effective data compaction — From Mixpanel and how they developed an event compactor system with PubSub.
- The 2 inventors of the Lempel-Ziv algorithm that is used in all ZIP files died recently. They wrote their proposal in 1977. RIP.
Sorry for this longer edition, and see you next week ❤️.
PS: if you follow me on LinkedIn you might see this content recycled there because.