
Hello here, this is Christophe from Amsterdam. I hope you're doing good. I'm in Amsterdam for the day for the DuckCon #4. The DuckDB annual conference, and god I like Europe. Being able to travel by train from Berlin to Paris to Amsterdam while going to the west of France for a lecture in a week is something truly awesome.
Anyway this week will be a mixed Data News with links, stuff and ideas and a small wrap-up of the DuckCon + the stuff I presented on Wed. to a Modern Data Stack meetup in Paris about DuckDB WASM. I hope you'll enjoy it.
The text-to-sql problem
Every once in a while the people are trying to give a shot at the text-to-sql problem. Each time a new breaktrough is happening (meaning a new LLM) company launch and people tries. 2 weeks ago TextQL raised $4.1m seed trying to solve this issue.
But what problem are we trying to solve?
In fact, I think we're trying to solve two different problems. The first is self-service, we want our stakeholders to be able to access information on their own and with no errors, once again chasing the dream that our clients can navigate the data jungle on their own, in fact this problem is "text-to-insights". And there's the second part of the problem which is much simpler, a data copilot, which can be a tool that accelerates the productivity of data workers by bootstrapping SQL writing or analysis.
Obviously when it comes to self-service we need a layer that does a text-to-sql conversion. In the current cycle of hype it can be done with LLMs, like DuckDB-NSQL-7B, the one MotherDuck provided recently. Like every model you have to analyse the efficiency of these generation layers.
From my own little experiments in this field here what I can say a generating layer can behave like an analyst but will be way more stupid than an analyst. I mean, on one side a LLM can get a thousands lines queries right the first time, like an analyst, it has to be done incrementally, either with prompt for the LLM or by test and run by the analyst.
But there is something that limits the LLM: his business understanding. Even if you give your LLM access to the database, the codebase and the docs there is something the LLM does not have: the implicit (vocal) business rules that are written nowhere.
I have 2 thing for the conclusion:
- Have a look at what Alan did as a Copilot / Metabase bot to help people getting insight — by people in this case it means the CEO, who is explicitly saying on LinkedIn "It's incredible I don't need to ask anymore my People or Data Analysts team" — 😬
- Having a data catalog does not mean that people knows what to do with the data [they just know it exists] —this is like an aggregate of quotes from my Wed. conference.
State of the French data market
2 benchmarks have been published recently about the French data market.
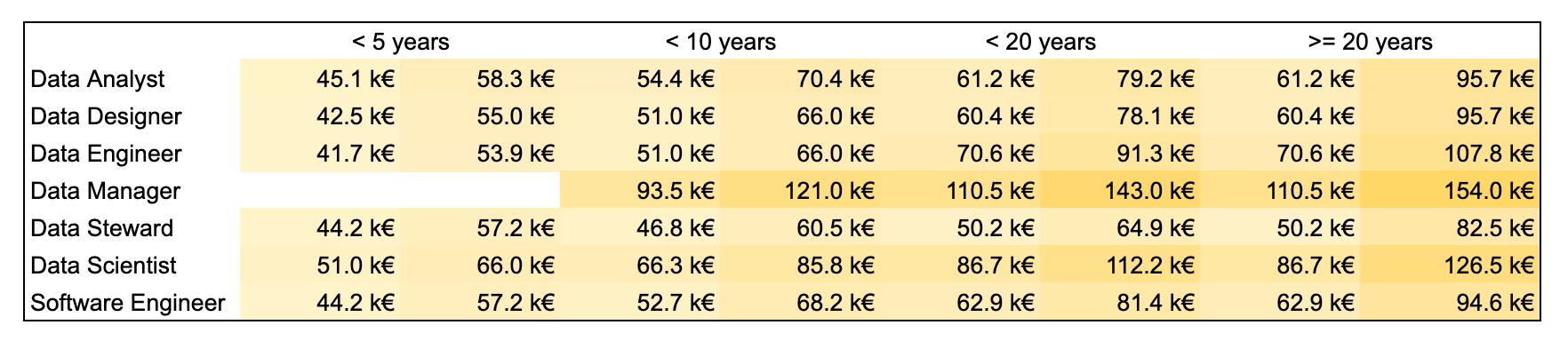
- The public sector released their salary grid for all tech workers — this is in French but scroll to the last page of the PDF to have the table
- We have 4 experiences buckets <5, <10, >10 and >20 years. Which is completely relevant for the tech / data field I think, only a few people are +20 years from what I see.
- This is crazy how bad data engineers are paid compared to all others positions — especially when you know that other positions are doing data engineering when there is no data engineers
- The comparaison to data scientists is nevertheless not relevant because very often data scientists have PhD. so make sense they start higher that other positions
- What do you think of it?
- At the same time the Modern Data Network released the annual benchmark of data professionals
- An Analytics Engineer role enters the chat — this is explained because the MDN is full of startup and roles evolves faster than elsewhere.
- This is complicated to compare the 2 benchmarks because the experiences ranges are not the same still we see trends that are similar between the positions.
- My main takeaway is that Data Analyst role is finally taking the place it should take as a full role and not a transition role before a DS or a DE role — being paid higher than other at entry for instance.

If you have been impacted by a layoffs and you need help finding your new journey, write to me.
Fast News ⚡️
Not to fragment the news that much because I already wrote too much AI News is blended without the Fast News.
- OLMo, a new open-source LLM — The Allen Institute in Seattle released what they called a truly open LLM. For the first time we have the model, the weights and the training data. I can't wait to see how it compares and used by people.
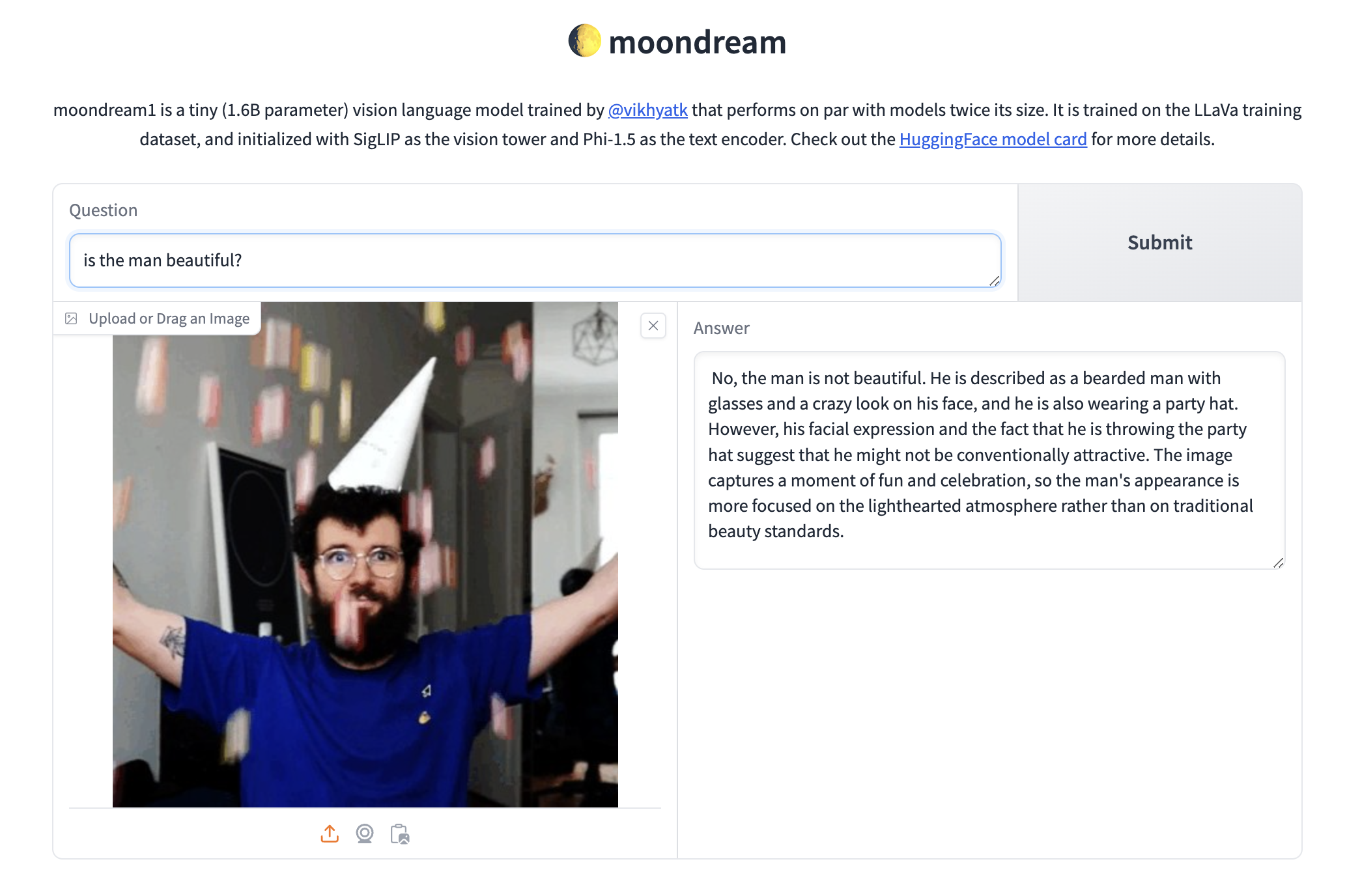
- hf/moondream1 — This is really awesome, this is a tiny LLM that can answer questions about a given image.
- :probabl. launch — The team behind scikit-learn is joining forces and creates a new venture with the goal to maintain a state-of-the-art data science tooling suite to benefit France, EU and the World.
- github/cybersec-ctf-box — A cybersecurity CTF to train yourself. A friend of mine created this repo to train yourself against a few attacks you might face. The first one is around Chart.js library.
- dbt Labs names a new CTO — He was CTO at MongoDB previously.
- Don't fix bad data, do this instead — This is never a good idea to apply patch on bad data. Always remember to identify root causes before jumping on the fixing wagon.
- Our transformation journey toward an open data platform — Condé Nast data platform walkthrough. The platform is built on-top of Databricks with a lot of other logos revolving around making sense of the lakehouse platform.
- Mastering Airflow variables — All the different techniques to master Airflow variables.
- Grab, rethinking stream processing: data exploration — How do you unlock analyst super-powers by giving them capabilities to analyse real-time data directly on streams and not in the offloaded lake data.
- How to build high-performance engineering teams — Get click baited like me. If I can add a following point, step 0 is important but then you need to give them enough freedom and vision.
- The business-critical data warehouse — Putting back the church at the center of the village.
- Databricks acquires Einblick — It goes back to the text-to-insights problem. Einblick is a drag-n-drop solution to "solve any data problem in one solution". LMAO marketing teams at the finest.
DuckCon + my Duck stuff
Because this Data News is already too long I split the content into 2 articles. Read my DuckCon takeaways 🦆.
Still last Wed. I've presented DuckDB to a French audience during this presentation I've showcased what you can do with DuckDB and DuckDB WASM. WASM is a portable way to run DuckDB in the browser.
You can play with the SQL editor I've worked on here (mobile + desktop), try to run a small group by query after a load tables, everything you do run on your device. This is the wasm magic. There is as well the Firefox extension the let's you hover parquet file in cloud console to get the schema, but more of this later as I plan to push it forward this month.
PS: I'm so happy to met a few readers IRL, it anchors my content and my work into the reality. So once again to the few people who came to me, thank you so much.
See you next week ❤️.