
Back on Friday release. Hi dear members you'll find below your beloved Data News. Enjoy 🎉.
Data fundraising 💰
Data team collaboration tools will probably be trendy in 2022. They are the last mile of the data exploration.
- This week we first got Canvas, a spreadsheet based tool that helps you explore your data without SQL — but they generate SQL from actions you do. They raised $4.2m in funding.
- And then Deepnote raised $20m in Series A to provide real time cloud based Jupyter compatible notebooks.
- On "low-code" predictive analytics side, Pecan raised $66m in Series C to continue develop their BI-friendly predictive tool. They sell it like a way to bootstrap data science without data scientists.
- Rudderstack raised $56m in Series B for their customer data platform. They sell a cloud platform where you send all your data (tracking, sales, marketing, ml, etc.) and they sync directly to your warehouse and/or to you favourite operational tools.
- Tilo raised €1.2m in pre-seed funding to create an entity resolution platform. They want to help you deduplicates entities in your database in order to beat fraud for instance.
New Fivetran pricing
Fivetran unveiled, 3 days ago, a new pricing that will make at least half of their customers happy (according to them). The new pricing changes are:
- Resyncs will be free for every connectors
- They are moving out of credits, pricing plan will be in dollars factor the Monthly Active Rows
- The entry cost will significantly be lower: $60 / month for 200k primary keys to sync
I found these changes very interesting because each time I speak we people about Fivetran the cost was a recurrent topic.
dbt community-led tooling
With dbt crossing the 10k weekly active projects this is the time to say that dbt is taking place at the centre of the ecosystem. That means that the community should start developing tooling around it to own it, to make it evolve. I came across 2 initiatives that may interest you:
- Interactive CLI search for dbt models with fuzzy finder (fzf-dbt) — fzf is a command line fuzzy finder that helps you search faster
- Features & Labels (fal.ai) is a team of engineers building tools to make it easier to deploy ML models and they started with dbt tooling with fal dbt and dbt model training is coming soon. Thanks to fal-dbt you can run for instance Python script from dbt Cloud without Airflow (with and not within — don't get clickbaited)

Where is Google Cloud going?
For a long time I have been pushing and advising BigQuery over all other warehouses vendors because I was convinced that is was easier on all aspects for data newcomers. Recently Google Cloud announced their results and this is not yet perfect: they extended their server life for 1 year and lost around $3b in 2021. But what does that mean for the future of Google Cloud?
2 years ago, rumours were saying that Cloud division had to become top 1 player to avoid losing funding. With these results and also the number of departures from BigQuery team to other data warehouses I've already reported I'm still waiting for an deeper vision and strategy from GCP.
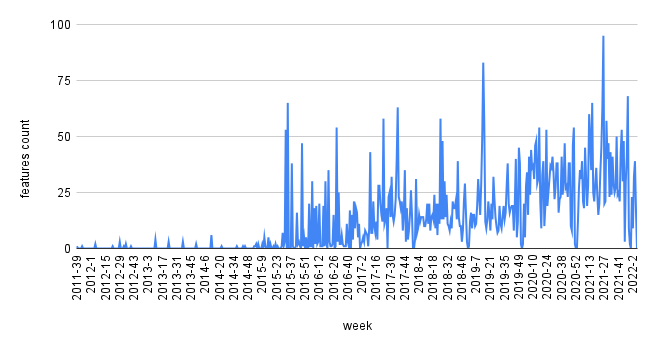
By curiosity I had a look at BigQuery releases pace — below — and it continued to increase since 2015 so even with departures Google is still present, phew.
The Analytics Engineer, 2022 most sexy job?
I bet 2022 will be the year where we'll see flourish the Analytics Engineer term. But what are companies expectations about Analytics Engineering? Obviously we can say SQL and dbt, which is already present in a lot — more than 1500 — of jobs.
ML Friday 🦾
Spotify team shared the platform they built in order to support their machine learning efforts: ML Home. This is a huge inspiration for all data teams in search of ml collaboration.
LinkedIn on the other side shared their DARWIN platform that allow data science team to do everything from Jupyter notebooks and well integrated with Datahub.

Events 📅
- April 26 2022 — Metrics Store Summit
- February 9-10 2022 — Data Mesh Summit
- February 8 2022 — Entropy - Data Obs Conference
Fast News ⚡️
- 5 things to know about Parquet — Marlene wrote a short note about what you should know about Parquet
- The baseline data stack — Seattle data guy wrote a series of article about the different kind of data stacks out there — from open-source to server less ones. This is a good overview article for beginners.
- Setting up data monitoring for Snowflake — Ivan popped out in my Twitter recently and I discovered Monosi, a new data observability solution. Let's see where it goes.
- Postgres WAL activities useful requests — if you want to explore your Postgres write ahead logs, this post will help you with useful requests.
- Metadata Guardian — A Rust open-source project that will scan your data sources in order to find any PII there.
- Building an SEO Data Pipeline
PS: small personal question, sometimes I'm asking myself if a Patreon based model could work for the newsletter. What do you think? Would you be willing to support the adventure for 2$-10$ per month (or more for companies)? Obviously the newsletter will stay free forever but you could have other perks.