Data News — Week 22.20
Data News #22.20 — One year after where are we? Imply and Heartex fundraising, dbt again, gender diversity and state of orchestration survey.

🎂🎂🎂 Happy birthday to the Data News 🎂🎂🎂. It has been one year since I've officially decided to publish on a weekly schedule my data curation. Some figures about the newsletter:
- ✍️ It represents 54 articles and 50298 words written.
- 💬 I've written the word data 1192 times. Airflow, dbt and Snowflake respectively 160, 140 and 95 times. You will find the 50 most_common words here.
- 📰 23905 emails sent and an average of 65% open rate. 31% of the member base opened more than 90% of their emails.
- ⏱ I've been late in the publication 12 times — published on Saturday.
- 😢 Sadly 54 people unsubscribed.
- 👀 The newsletter web pages represented 8k page views with an average of 4m15s reading time. The must read articles edition has been the most viewed. I plan to do something similar soon.
Regarding the blog I've added a comments system on each post and you can also like posts to show support. And I decided to change the versioning of the news, it'll be <year>.<weeknumber> .
I did not finish the rework of the Links page and I hope it'll be out next week. If you want to test it in beta before others please reach out. Thanks to the Links Explorer you will be able to search, browse and bookmark all links that have been shared previously.
Once again thank you for the support ❤️.
Data fundraising 💰
- Imply raised $100m in Series D, the Californian startup has been founded by Apache Druid creators. They provide Druid as a cloud service — they call it DBaaS. With this Series they plan to add better tooling around Druid, especially with SQL capabilities for ingestion and ETL and better joins support.
- Heartex announced a $25m Series A to build the best end-to-end solution for managing data labelling projects. They open-source their Label Studio which seems amazing, it includes only core labelling features, teams stuff is in their enterprise version.
- This is not really data related. But I like the promise of having a tool that is able to search over the knowledge of a whole company. Glean raised $100m in Series C. They provide a platform that indexes your whole app ecosystem data and then provide a search experience over everything. Their approach is similar to data catalogs products but different. It looks like something to get inspiration.
Increase gender diversity in engineering
I hope I'm doing a good job when it comes promoting articles from women or non-binary. On same topic 50inTech, a initiative that promotes safe workplaces for women did an interview with Iman Akabi who is Lead Data Engineer where she shares what she's doing and how she became data engineer.
When you look at data teams we are closer to gender parity compared to usual tech teams. But this is biased, data engineering gender ratio is worst than software engineering while data analysts one is close to 50-50. This is based on US number, but it also verifies on my close data entourage here in France.
We have work to do.
Batch or stream?
Choose between batch or stream, Benjamin from Popsink tried to summarized what you have to look at when choosing an architecture. Personnaly I still always advice batch for analytics without a lot of volume, but stream products are catching up when it comes to tooling to make streaming a commodity.
Stripe Data Pipeline
Stripe announced Data Pipeline, a service to ship your Stripe data directly to your warehouse — Redshift and Snowflake are supported. I find this interesting because Stripe as a reputation of well crafted products that just works once you use it.
But why on hearth Stripe decided to ship this kind of service when there are plenty of solutions out there to sync data? It's probably because they listened customers complaining about the poor data ingestion ecosystem and fixed the problem to the roots. They own a Data Pipeline solution. Tho, I don't get their pricing, 0.03€ per transaction, what does that means?
Under the hood they are using Snowflake and Redshift Data Sharing features. Will it start a trend for other SaaS tools. Let's provide data sharing to get rid of APIs ingestions.
dbt again
Following last week discussion between Pedram and Tristan, Jeremy who works on dbt-core at dbt Labs wrote the 2022 roadmap vision, he announced 2 new minor releases for this year:
- 1.2 → with a refactor on incremental models, support for grants, migrate dbt-utils to core and improve it and Python models in beta
- 1.3 → Python models, UDFs definition from dbt, better exposures and external nodes (it means dbt DAG calling REST API to do stuff)

State of workflow orchestration
This week Prefect released a report on the state of workflow orchestration ran by Ben Lorica, an AI advisor and influencer. In the survey you'll see mainly that the field is still dominated by Airflow 36%, with behind Prefect 14% and Dagster 8%. Surprisingly Argo is well positioned with 8% as well.
In also have trouble to explain the figure below saying that analysts are using Airflow mainly while having MS-Word as their second most important skill (another figure in the survey).
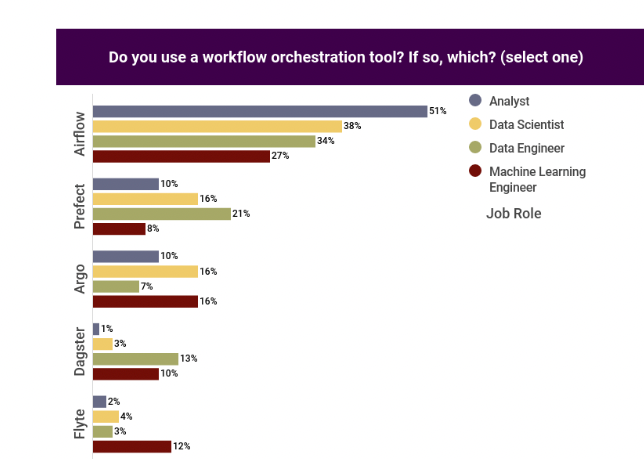
I feel that the survey depict the field quite well with no big surprises.
Fast News ⚡️
- LinkedIn engineering blog is an awesome resource when it comes to machine learning. This time they are sharing ideas around their MLOps portal.
- Working with large JSON files in Snowflake — Great walkthrough for JSON manipulation with Snowflake. He even uses Java UDFs 😬.
- Data warehousing schemas types — Understand visually star, snowflake and fact constellation schemas.
- Scaling data access by moving an exabyte of data to Google Cloud — Twitter moved 1 exabyte of data (1018 bytes) from Thrift in HDFS to Google Cloud in BigQuery.
- Future of the Metrics Layer — Video and transcript about what sorcery is the metrics layer. In addition David spoke about the cache that will be a key part in any metrics layer.
- Data Lakehouse explained
- Setup Debezium of Kafka, a walkthrough
This is the Airflow Summit next week, if you are in France come see us at local event. Also send me the talks you would like me to cover in my usual afterwards takeaways 👋

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.