dbt multi-project collaboration
Use cross-project references without dbt Cloud. This article showcases what you can do to activate dbt multi-project collaboration.

Over the last few years, dbt has become a de facto standard enabling companies to collaborate easily on data transformations. With dbt, you can apply software engineering practices to SQL development. Managing your SQL patrimony has never been easier.
So, yes, dbt is cool but there is a common pattern with it: you accumulate SQL queries. If your implementation of dbt is successful, many teams will use it, many business use cases will result in SQL queries in your warehouse. Fast forward to 2 years later, you find yourself with hundreds or thousands of SQL queries. Whatever the number, there will be a critical point at which a single project no longer scale.
Having too many models in a single repository will become unmanageable:
- Governance — many data owners
- Data domains — a lot of different concepts that you would like to isolate as single units
- Name clashes — you can't have 2 models with the same name in a project
- and more 😅
This is when you consider a multi-project configuration for your dbt implementation. With a multi-project configuration, you can imagine isolated dbt projects with possible connections between them. We can draw a parallel with microservice architecture. Each dbt project is like a microservice and instead of exposing an HTTP API, it exposes tables with enforced contracts.
Initially cross-project references was a feature aimed to be released in dbt Core (cf. roadmaps 2022-08 and 2023-02). But after research and first developments it was decided by dbt Labs that multi-project collaboration will become a feature of dbt Cloud. Which I understand perfectly. It's the best feature for creating a differentiating commercial offering. What's more, multi-project collaboration is by its very nature an Enterprise—with a big E—feature, which makes it relevant for a paid-for solution.
Hence dbt Mesh, which has been announced this week at Coalesce—dbt Labs annual conference. dbt Mesh is the dbt Cloud solution to manage cross-project references, a multi-project node explorer and all the governance.
Cross-project references is a key enabler to data team decentralisation. Let's imagine you have a core project, managed by the central data team. In this core model you have an orders model. On the other side the finance data team wants to build a revenue model on top of the core.orders model. With cross-project references you can declare a model to be public on core to use it elsewhere.
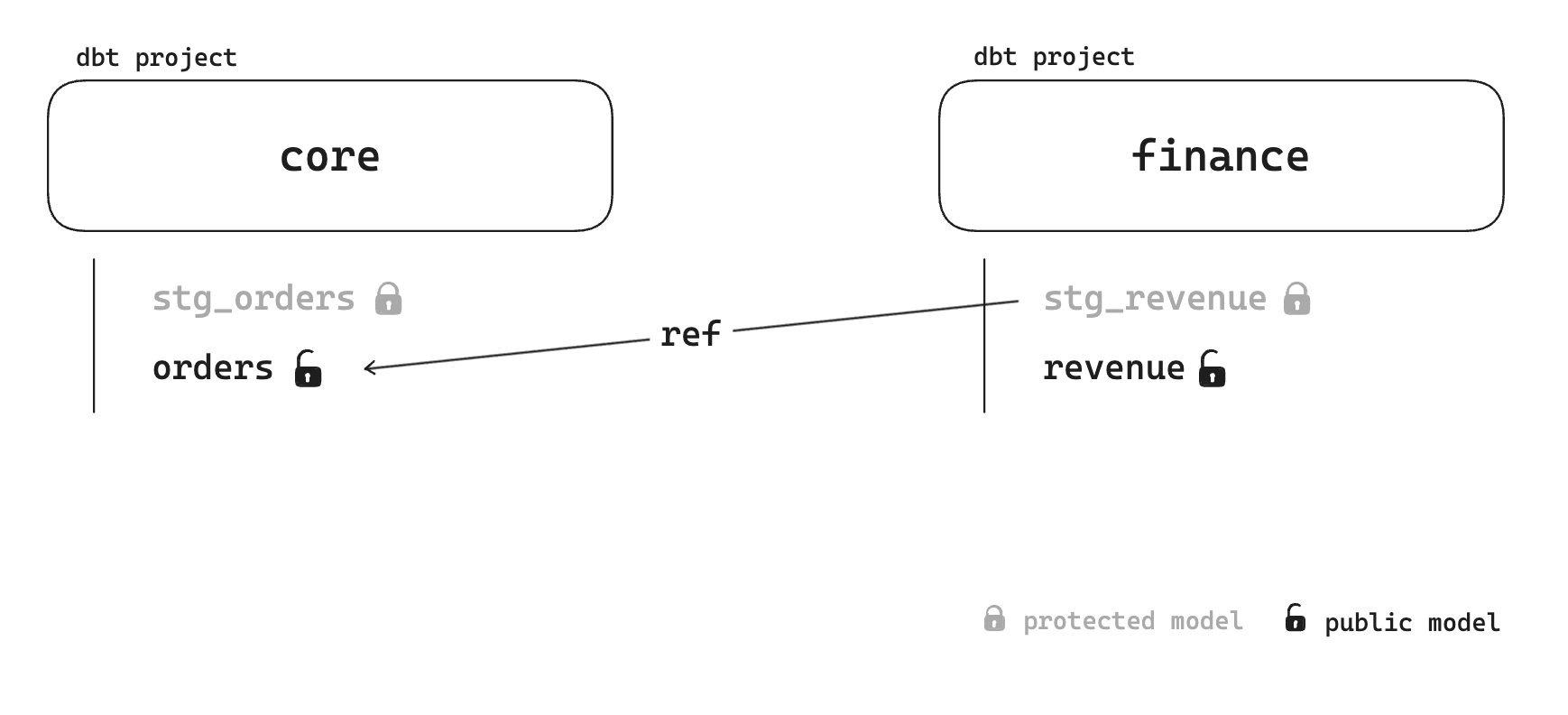
All this is possible natively with dbt Cloud. But dbt Cloud multi-project is expensive. At the very least $100/month per project—Enterprise pricing, so it's not possible to have actual figures. But from what I know, it's expensive.
What if we could do it with dbt Core?
Enters dbt-loom
Obviously the community did not welcome well this announcement as it converged with the new pricing. It's a bit frustrating to see a product you truly love and I which you believe keeping awesome features behind closed-doors. But dbt is still open-source, so it's up to the community to adapt.
And the community adapted.
On my side I tried to fork dbt-core to inject in the what was need to make the multi-project working, but it was a burden. It was not very successful. On the other side Nicholas Yager worked on dbt-loom which leverages new dbt Plugins mechanism that was introduced with v1.6. Nicholas wrote a great explanation of the plugin API.
Under the hood, you need to write a Plugin class, inheriting from DbtPlugin, and implementing one of the 2 hooks available—or both: get_nodes and get_manifest_artifacts . The first hook is called every time dbt needs to get nodes and nodes are injected as external nodes, this is the one that interest us. Actually if we want to implement cross-project dependencies we need to add to a dbt project context the external nodes it depends on.
Here what you can do with dbt-loom.
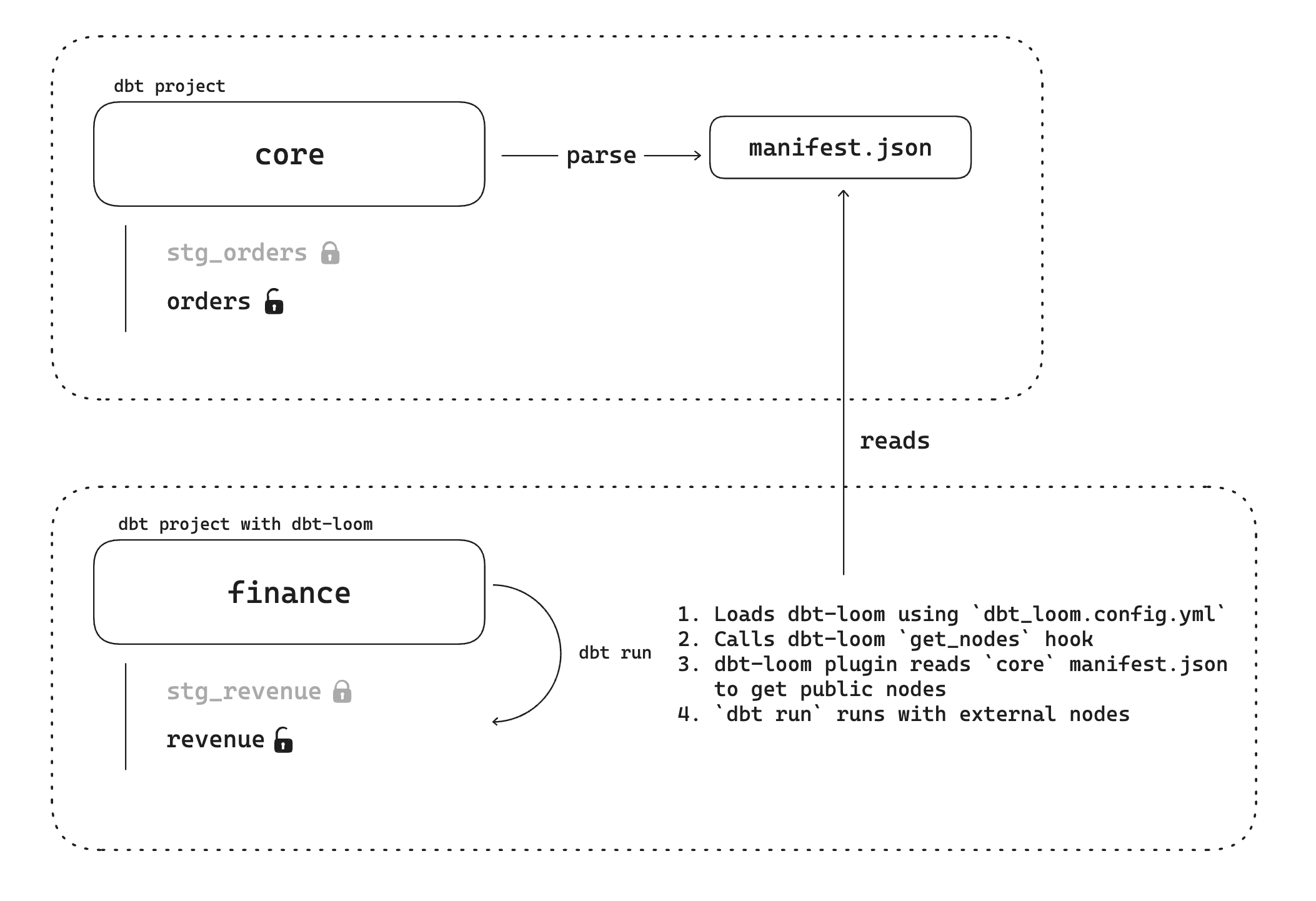
Multi-project collaboration example
In order to help you understand what it really means here a working example with dbt-loom on a 2 projects setup—core and finance. First in the core project. In order to have reproducibility I use dbt-duckdb connector so everyone can try it at home. I have 1 seed that loads a few rows and 2 models: stg_orders and orders.
Obviously orders depends on stg_orders and respectively the first one is public and the second one is private.
-- raw_orders.csv (dbt seed)
order_id,order_date,amount,customer_id
1,2023-01-01,340,c1
2,2023-01-02,13,c2
3,2023-01-03,1456,c1
4,2023-01-04,765,c3
-- stg_orders.sql
WITH raw AS (
SELECT
order_id,
order_date::DATE AS order_date,
customer_id,
amount
FROM {{ ref('raw_orders') }}
)
SELECT *
FROM raw
-- orders.sql
SELECT
order_id,
order_date,
customer_id,
amount::DECIMAL(8,2) AS amount_incl_vat,
(amount / 1.2)::DECIMAL(8,2) AS amount_excl_vat
FROM {{ ref("stg_orders") }}The seed, the stg model and the final public model.
In order to declare these models as available for cross-project dependencies you need to specify it in the YAML. In our case stg_orders will be protected and orders will be public with an enforced contract. The contract is super important because as soon as you expose a model, you have to potential downstream consumers that are building stuff on your models, you can't delete a column or change a type without notifying. Or even more, versioning models.
version: 2
models:
- name: stg_orders
access: protected
- name: orders
access: public
config:
contract:
enforced: true
columns:
- name: order_id
data_type: int
constraints:
- type: not_null
- name: order_date
data_type: date
- name: customer_id
data_type: string
constraints:
- type: not_null
- name: amount_incl_vat
data_type: numeric(8,2)
- name: amount_excl_vat
data_type: numeric(8,2)models.yml that declares access and contracts for public model
That's all for the core project. Once you have dbt build the core project a manifest.json will be generated and tables will be created in the database. On the finance project, with dbt-loom install—pip install dbt-loom— you need to declare the core project as a dependant manifest.
manifests:
- name: core
type: file
config:
path: ../core/target/manifest.json
dbt_loom.config.yml
Then you can write a few models that are using cross-project references.
-- stg_revenue.sql
WITH orders AS (
SELECT *
FROM {{ ref('core', 'orders') }} -- this is cross-project reference
)
SELECT *
FROM orders
LEFT JOIN {{ ref('margins') }} ON 1 = 1
-- revenue.sql
SELECT
order_date,
SUM(amount_excl_vat * margin) AS revenue
FROM {{ ref('stg_revenue') }}
GROUP BY order_datedbt finance project SQL models
Now you can dbt build this project as well and dbt-loom will extend dbt models list thanks to the plugin by adding the core.orders model.
In order for you to try it at home I've created a Github repository with a working example using DuckDB as database. You can try it yourself.
Conclusion
Multi-project collaboration is probably the best feature dbt Labs introduced in recent times. This feature has a huge potential to structure dbt projects and avoid chaos.
As a data engineer who loves open-source and community stuff, dbt-loom is a great workaround, but be aware that it's all experimental at the moment and if large workflows rely on this functionality, you should consider using the paid version with dbt Mesh.
In order to go further you can watch a Coalesce 2023 talk about dbt-meshify a tool that helps you automating your journey to a multi-project dbt setup from a monolith—here the direct link to the video.

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.