This article is meant to be a resource hub in order to understand dbt basics and to help get started your dbt journey.
When I write dbt, I often mean dbt Core. dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. dbt Core has been developed by dbt Labs, which was previously named Fishtown Analytics. The company has been founded in May 2016. dbt Labs also develop dbt Cloud which is a cloud product that hosts and runs dbt Core projects.
In this resource hub I'll mainly focus on dbt Core—i.e. dbt.
First let's understand why dbt exists. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. This switch has been lead by modern data stack vision. In terms of paradigms before 2012 we were doing ETL because storage was expensive, so it became a requirement to transform data before the data storage—mainly a data warehouse, to have the most optimised data for querying.
With the public clouds—e.g. AWS, GCP, Azure—the storage price dropped and we became data insatiable, we were in need of all the company data, in one place, in order to join and compare everything. Enter the ELT. In the ELT, the load is done before the transform part without any alteration of the data leaving the raw data ready to be transformed in the data warehouse.
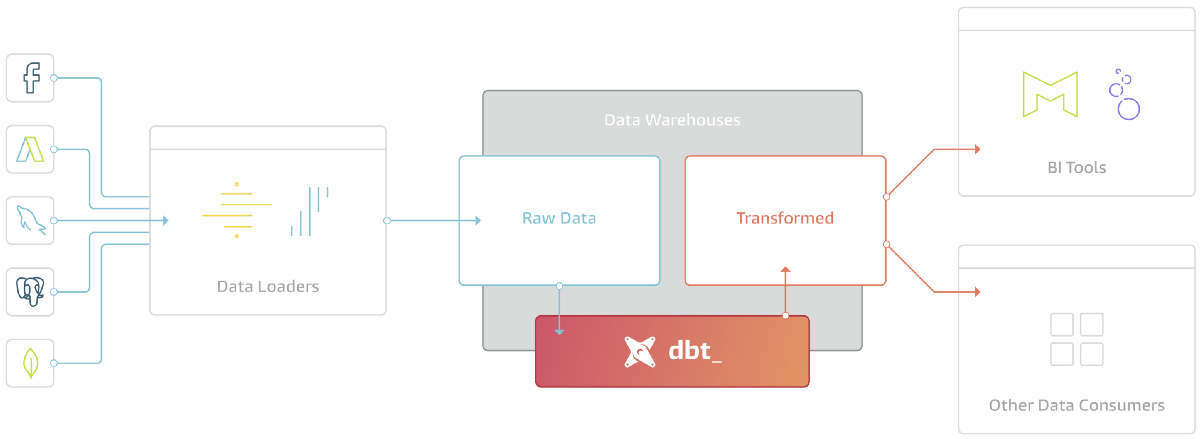
In a simple words dbt sits on top of your raw data to organise all your SQL queries that are defining your data assets. And dbt only does the T of the ELT which is really clear in term of responsibilities.
dbt is a development framework that combines modular SQL with software engineering best practices to make data transformation reliable, fast, and fun.
It was the previous tag line dbt Labs had on their website. This is important to understand that dbt is a framework. Like every framework there are multiple hidden pieces to know before becoming proficient with it. Still it very easy to get started.
dbt concepts
There are a few concepts that are super important and we need to define them before going further:
- dbt CLI — CLI stands for Command Line Interface. When you have installed dbt you have available in your terminal the
dbtcommand. Thanks to this you can run a lot of different commands. - a dbt project — a dbt project is a folder that contains all the dbt objects needed to work. You can initialise a project with the CLI command:
dbt init. - YAML — in the modern data era YAML files are everywhere. In dbt you define a lot of configurations in YAML files. In a dbt project you can define YAML file everywhere. You have to imagine that in the end dbt will concatenate all the files to create a big configuration out of it. In dbt we use the .yml extension.
- profiles.yml — This file contains the credentials to connect your dbt project to your data warehouse. By default this file is located in your
$HOME/.dbt/folder. I recommend you to create your own profiles file and to specify the--profiles-diroption to the dbt CLI. A connection to a warehouse requires a dbt adapter to be installed. - a model — a model is a select statement that can be materialised as a table or as a view. The models are most the important dbt object because they are your data assets. All your business logic will be in the model select statements. You should also know that model are defined in .sql files and that the filename is the name of the model by default. You can also add metadata on models (in YAML).
- a source — a source refers to a table that has been extracted and load—EL—by something outside of dbt. You have to define sources in YAML files.
- Jinja templating — Jinja is a templating engine that seems to exist forever in Python. A templating engine is a mechanism that takes a template with "stuff" that will be replaced when the template will be rendered by the engine. Contextualised to dbt it means that a SQL query is a template that will be rendered—or compiled—to SQL query ready to be executed against your data warehouse. By default you can recognise a Jinja syntax with the double curly brackets—e.g.
{{ something }}. - a macro — a macro is a Jinja function that either do something or return SQL or partial SQL code. Macro can be imported from other dbt packages or defined within a dbt project.
- ref / source macros —
refandsourcemacros are the most important macros you'll use. When writing a model you'll use these macros to define the relationships between models. Thanks to that dbt will be able to create a dependency tree of all the relation between the models. We call this a DAG. Obviously source define a relation to source and ref to another model—it can also be other kind of dbt resources.
In a nutshell the dbt journey starts with sources definition on which you will define models that will transform these sources to something else you'll need in your downstream usage of the data.
dbt entities
I don't want to copy paste the dbt documentation here because I think they did it great, there are multiple dbt entities—or objects, I don't know how to name it, they name it resources, but I don't want to clash with the resource as a link. So there are multiple dbt entities you should be aware of before starting any project, the list below is exhaustive (I hope) but more, the list is sorted by priority:
- sources / models — you already know it, this is the key part of your data modelisation.
- tests — a way to define SQL tests either at column-level, either with a query. The trick is if the query returns results it means the test has failed.
- seeds — a way to quickly ingest static or reference files defined in CSV.
- incremental models — a syntax to define incrementally models with a if/else Jinja syntax. Here the reference. You can choose the strategy you want depending on your adapter (cf. examples on BigQuery).
- snapshots — this is how you do slowly changing dimension. This is a methodology that has been designed more than 20 years ago that optimise the storage used. The dbt snapshot page is the best illustration I know of the SCD.
- macros — a way to create re-usable functions.
- docs — in dbt you can add metadata on everything, some of the metadata is already expected by the framework and thank to it you can generate a small web page with your light catalog inside: you only need to do
dbt docs generateanddbt docs serve. - exposures — a way to define downstream data usage.
- metrics — in your modelisation you create dimensions and measures mainly, in dbt you can next define metrics that are measures group by dimensions. The idea is to use metrics downstream to avoid materialising everything. You can read my What is a metrics store to help you understand.
- analyses — a place to store queries that are either not finished either queries that you don't want to add in the main modelisation.
You can read dbt's official definitions.
Also dbt only does a pass-through to your underlying data compute technology, there is not any kind of processing within dbt. Actually dbt can be seen as an orchestrator with no scheduling capabilities.
Analytics engineering
dbt is becoming a popular framework while being extremely usable. A lot of companies have already picked dbt or aim to. There are multiple technological reasons for this, but technology is rarely the real reason. I think the reasons dbt is becoming the go-to are mainly organisational:
- dbt is a complete tool that you can give to analytics teams, it can become their unique playground. Within it they can do almost everything.
- The network effect. Because more and more companies are betting on it, more and more trained people there will be in the market. It's also a strategical choice in order to be able to hire people.
- The documentation, as I said earlier, is top of the notch.
dbt Labs also popularised the analytics engineer role. We can quickly summarise the role as in-between the data engineer and the data analyst. But because companies can have very versatile definition of role, I'd say that the analytics engineering is the practice to create a data model that represents accurately the business and that is optimised for a variety of downstream consumers. So the analytics engineers are the one doing this.
By the position of this role and the freshness of it, people are coming into analytics engineering from data analytics. Usually they don't have a lot of software engineering good practices and knowledge, which is obvious, but the dbt framework is also meant to bring this to the table.
This is also fair to say that dbt as a tool is very easy to use and very often the complexity of the dbt usage will lie in the SQL writing rather than the tool usage by himself. There are also a few questions in term of project structuration that needs to be done.
If you like this article you should subscribe to my weekly newsletter to not miss any other article of this kind.
Resources
As I only want to help you get started with concepts I know want to redirect you to other articles that I find relevant to go deeper:
- dbt annual conferences — Every year dbt do their annual conference called Coalesce which features a lot of dbt user and usage. I've covered with takeways the 2 last one: Coalesce 2021 and Coalesce 2022. In these articles there are a lot of cool presentations you should watch to understand deeper how dbt works.
- Introduction slides about dbt — This is a presentation I often give, you can also watch a talk I gave in French, there is also a great introduction by Seattle Data Guy that I recommend.
- You can do tests in dbt — like: environment-dependent unit testing in dbt, 7 dbt testing best practices or a guide to building reliable data with dbt tests.
- You have to get inspiration from others dbt projects — dbt @Beat, dbt @Vimeo, dbt @ShopBack.
- Optimisation — An issue with dbt is that everything will run in SQL, which means you'll have to optimise a lot of thing. dbt Labs team wrote about an optimisation of a long running model.
- A rant against dbt ref — A great article to make you think about dbt principles.
- How to monitor dbt models.
- Generate databases constraints with dbt.
- 🧑🏫 Online courses — I've tried any of the courses I'll recommend, but from the background of the mentors I think they are very relevant. There is first a Corise "Data modeling for the modern data warehouse" that lightly covers dbt and mainly how to do data modeling and the analytics engineers club that sells a training program to go "from analysts to engineer" in 10 weeks taught by an ex-dbt Labs employee. You can also contact me if you want something more personalised.