Introduction to Airflow concepts
Getting started with Airflow, understand what are the basic concepts of Airflow and where to get started.
Understand Apache Airflow's architecture and basis.

What is Airflow to Data Engineering?
Data Engineering is a relatively new engineering field, and as our society becomes more and more data-oriented, Data Engineering has become a core stake in the data utilization process. Creating data pipeline has become an essential practice for any data exploitation model.
Apache Airflow was quick to become one of the most used tool for Data Engineers to orchestrate their data pipelines. This open source platform was born in Airbnb’s headquarters, to overcome the massive amount of data they have to deal with. In 2016, Airflow joins Apache’s incubator and becomes Apache Airflow.
Airflow has been created by Maxime Beauchemin while at Airbnb. With his vision of the discipline Maxime revolutionized how company treat data today. He wrote his vision on his medium. Even 5 years after everything he said is still relevant.

Airflow’s architecture
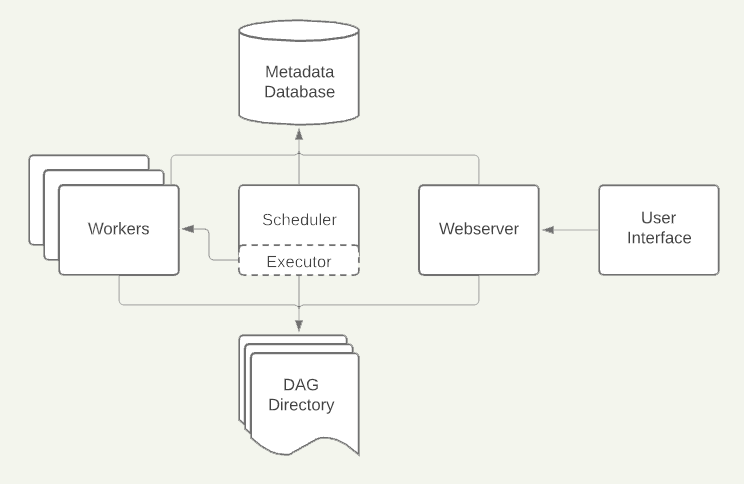
Concept
Airflow is a workflow orchestration tool, that allows you to build, schedule and monitor data pipelines.
The way Airflow works is the following: you schedule a workflow which is made by Tasks and their dependencies. A Task can be created based on an Operator (link), for instance we have the PythonOperator or the BashOperator. Once created the Tasks can be added to a DAG (directed acyclic graph) — which means the "pipeline". The DAG is then parsed and scheduled by the Scheduler. Then depending on the architecture you decided your tasks are picked up and ran inside the Executor by either the scheduler either some workers.
If it seems a bit complicated, you’re in the right place! We’re about to explore in detail each keyword above.
Tasks
A Task is the smallest unit in Airflow’s architecture. Tasks are basically jobs to be executed and can be made out of Operators, which are pre-existing templates. For example, here’s an Airflow task using the BashOperator.
from airflow.operators.bash_operator import BashOperator
bash_task = BashOperator(
task_id='bash_task',
bash_command="echo 'my-command'",
)There are many more basic Airflow such as PythonOperator, EmailOperator, but also many custom-made Operators created by Airflow’s community. More information here. There is also a Registry out there.
DAG and Task dependencies
Tasks are defined inside a DAG, or Directed Acyclic Graph. A DAG is a graph that is directed and without cycles connecting the other edges, which means each node is in a certain order. Here’s a mathematical example of a DAG.
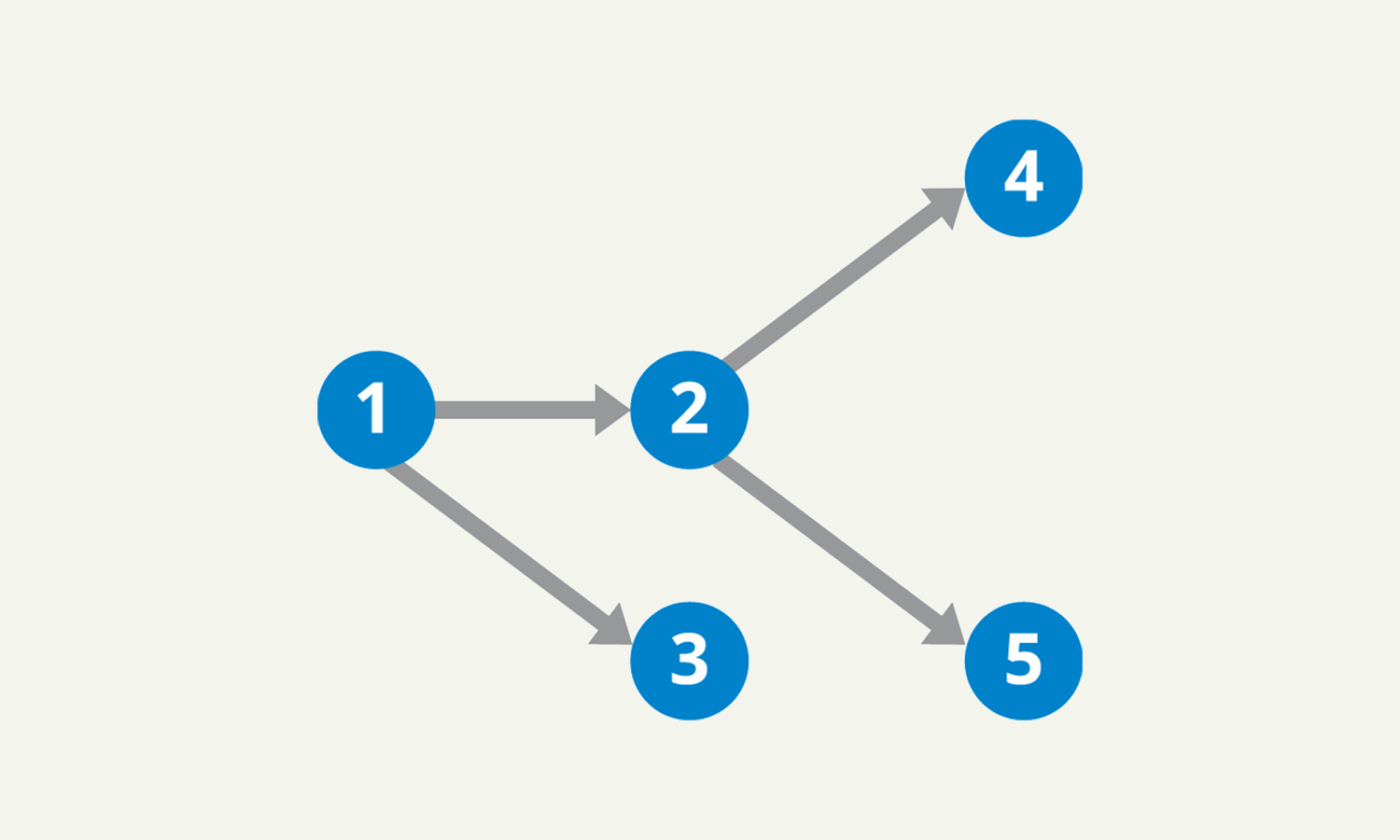
And here’s an example of an Airflow DAG, in Python.
from airflow import DAG
from datetime import datetime
from airflow.operators.bash_operator import BashOperator
from airflow.operators.email_operator import EmailOperator
with DAG(
"my-dag",
start_date=datetime(2022, 01, 20),
schedule_interval="@daily",
) as dag:
bash_task = BashOperator(
task_id='bash_task',
bash_command="echo 'my-command'"
)
email_task = EmailOperator(
task_id='send_email',
to='to@gmail.com',
subject='Airflow Alert',
content="my-content"
)
bash_task >> email_taskAt the end of a DAG, it is mandatory to specify Task dependencies as you see in the example above.
If we take a look back at the mathematical DAG above, here’s how the Task dependencies would look like:
1 >> [2, 3] >> [4, 5]Scheduler and Executor
Once the DAG is set and is placed in the DAG folder, the Airflow Scheduler will take care of triggering the Task and and sends it to the Executor chosen.
Executors in Airflow are where Tasks ran. Specifying an Executor is mandatory. If you’re looking for a simple way to run your Airflow DAGs, you are most likely looking for the Local Executor. Here’s more information about Airflow’s Executors.
Airflow's Executor receives a Task by the Scheduler, and will queue it to be executed by a Worker. The Executor handles operations at Task-level, while the Scheduler handles operations at DAG-Level.
Workers
Workers are the entities that actually execute a Task. The number of Workers available for a DAG and their type is specified in the DAG's Executor.
Webserver
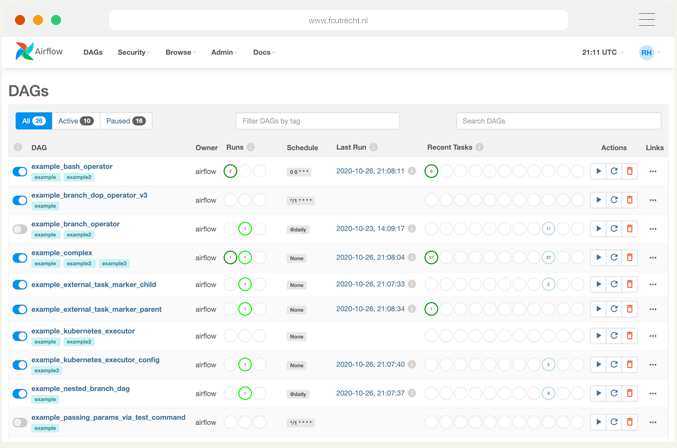
Airflow’s Webserver is a UI that allows to monitor and debug DAGs and Tasks. Here’s Airflow’s UI where we can manage DAGs, Tasks, schedules and runs.
Airflow commands explained
In the latest version Airflow commands renewed and are more intuitive than ever. Below a quick overview of each of them. The complete documentation is available on airflow website.
scheduler
airflow scheduler→ Command to launch the scheduler process, if you want to run it in the foreground pass the -D option.
webserver
airflow webserver→ Command to launch the webserver process, by default it will run on the port 8080 and on all interfaces "0.0.0.0". Like the scheduler if you want to run it in foreground pass the -D.
db
airflow db init
airflow db migrate
airflow db ...→ In order to launch an Airflow instance you'll need to have a database (can be SQLite locally for instance). Airflow db commands group will help you manage your database, with the init you'll create the tables in the database and with migrate you'll apply the migrations if you already have tables but you apply a new release.
users
airflow users create –username admin –firstname FIRST_NAME –lastname LAST_NAME –role Admin –email admin@example.org→ You'll for sure need an user to access your Airflow UI, and this command will let's you create your first admin user. Don't forget to change the options while running it production ;)
dags & tasks
airflow dags <subcommand>
airflow tasks <subcommand>→ These two commands are super powerful and will help run and/or test your pipelines before scheduling them in production. I really like the airflow tasks test command that allows you to run a specific task without meeting any dependencies.
Deploying your pipeline
The easiest way to run Airflow is to run it inside a Docker container, tutorial here. However, we'll see below possibilities to deploy Airflow in production using cloud services.
Google Cloud Composer
Cloud Composer is a fully managed workflow orchestration service built on Apache Airflow. Here's the official documentation on how to get started.
AWS
Amazon also has a workflow management tool called Managed Workflows for Apache Airflow (MWAA), overview here.
Astronomer
Alternatively, you can try out Astronomer, the enterprise framework designed for organization use of Airflow. Check our feedback article about Astronomer along with a full tutorial on deployment.
Quick tips
And finally, here are some Airflow tips from Christophe.
- Use aliases to jump in your Airflow workspace easily — each day when you start to work on Airflow you will need to activate or change directory. In order to have a nice fresh start, use aliases to jump in faster in your project. My generic alias is this one.
- Prefix or suffix all your DAG names — In order to have a better visual sort once loading the UI I recommend prefixing your DAG names by the frequency (daily, weekly, monthly) and at least the step of the ETL the DAG is in.
- Use factories to create DAGs — Data engineers are not meant to write DAG, they are better at writing software, so prefer using factories to create DAGs to factorize the common configuration of all your DAGs. It will save you time in the future. For instance you can use a create_dag function.
If you liked this post do not hesitate to tell us on Twitter we can do a second part where we'll deep dive into more advanced Airflow concepts.

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.